|
Es un método general de codificación y compresión diseñado para minimizar el número medio de bits necesarios para transmitir un símbolo cuando se debe transmitir varias copias independientes y estadísticamente equivalentes de dicho símbolo. Este método determina cómo los distintos valores del símbolo deben representarse como cadenas binarias. Supongamos que tenemos que enviar el símbolo X que puede tomar valores {x1,...xn} con probabilidad {p1,...,pn}. La idea es reservar palabras cortas para los valores más frecuentes de X. Este método no requiere usar ningún tipo de separador entre los valores.
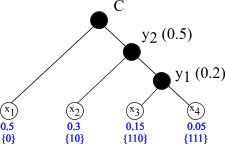
El código del ejemplo es de longitud variable, pero no se requiere usar ningún tipo de separador entre los valores.
La razón es que siempre puede reconocer el final de una palabra porque ninguna otra palabra es el principio de otra dada. Un código con esta propiedad se denomina código prefijo. El código Huffman es el código prefijo que requiere el mínimo número medio de bits por símbolo. |
Para derivar el código Huffman se hacen las siguientes operaciones:
El código queda definido por el camino desde C a cada nodo.
La convención para escribir el código de Huffman final
es: |